メディア・パブなぜ大手ネット企業が一斉に
人工知能技術開発に乗り出したのか。
(2014.02.28)

グーグルだけではない。フェイスブックやヤフーも、さらにバイドゥ、ピンタレスト、ドロップボックス、ネットフリックスといった若いネットサービス企業までも、一斉にAI(人工知能)の研究者や開発者をかき集め、競って開発体制を整備している。
これらハイテク企業が運用するソーシャルメディア・サイトでは、ユーザーの提供情報や行動履歴などの膨大なデータ(ビッグデータ)が宝の山となり、ビジネスの武器となっている。フェイスブックは毎日約500テラバイトもデータベースに蓄えているという。
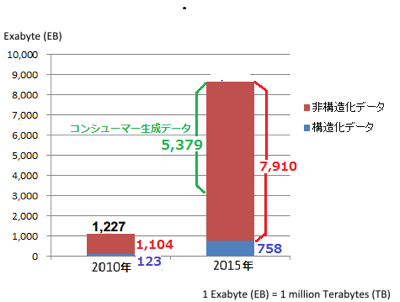
ところが活用しているデータ、つまりコンピューターで扱えるデータは、これまでテキスト系の構造化データが中心であった。一方でこれから摂取するデータは非 テキスト系で非構造化のものが、爆発的に増えてこようとしている。本格的なビッグデータ時代到来ということで、IDC が調査したレポートによると、データベースに蓄えられていくデータ量は2015年までに約8,500エクサバイトに積み上がると予測している。その9割以上が非構造化データである。さらに注目すべきは、その非構造化データの7割近くがユーザー(消費者)が生成するデータであることだ。つまり、ソーシャルメディアで生成されるデータが多くなるということだろう。
こうした類のビッグデータをいかにビジネスで活用できるようにしていくかが、これからのネット企業の勝負どころになろうとしているのだ。そのデータの種類も、既にそうなってきているが、テキスト系よりも写真や動画などの非テキスト系データの割合がグンと増えてきている。たとえば有力なソーシャルサイトでは、毎日、次のように大量の写真データが投稿・共有されている。
・フェイスブック・ユーザーは毎日3億5000点の写真をアップロードしている
・ワッツアップ・ユーザーは毎日5億点の写真をアップロードしている(最近ワッツアップをフェイスブックが買収)
・スナップチャット・ユーザーは毎日4億点のスナップ(snap)をアップロードしている
・インスタグラム・ユーザーは毎日5500万点の写真をアップロードしている
ところが、写真のような画像データも、タグ(ラベル)付けされておれば、ビジネスで利用できるのだが、そうでないと無用の長物になりかねない。ソーシャルメディア上で消費者(ユーザー)が投稿する画像(写真)から、商品やブランドロゴ、人物などが特定できれば、マーケターにとって膨大な写真がまさに宝の山になる。でも一日当たり億点以上も生成される画像にそれぞれ人手でタグ付けしていくのは、不可能である。そこで自動で画像のタグ付けを目指して、AIによる画像認識に大きな期待が寄せられているのだ。中でも切り札として、ディープラーニングと称する機械学習技術に熱い期待が集まっている。AI技術を競う各種コンテストで、ディープラーニングが圧倒的な成績で連勝していたからだ。画像の分類問題のコンテストでも桁違いの成績を収めた。
画像認識の機械学習システムの場合を見てみよう。たとえば人手で犬とタグ付けした犬の画像をたくさん機械学習システム(人工知能)に入力し学習させておけば、新たに入力された画像が犬であるかどうかを自動で識別できるようになるということだ。さらに猫とタグ付けした猫の画像も学習させておけば、未知の画像を与えてもそれが犬か猫かも識別できるようになる。でも、人手でタグ付けした画像で学習させるのは結構面倒である。そこでフェイスブックやインスタグラムのサービスで、ユーザーに投稿写真に対し写真のなかのオブジェクトや人物のタグ付けをしきりに勧めている。それは、機械学習のためにもなるか らだ。たくさんのユーザーと投稿写真を抱えているソーシャルメディアでは、機械学習も数多く自動的に行えるので、画像認識の質を高めることができるという。
フェイスブックのAI研究所長に就任したLeCun氏がWiredのインタビューの中で、グーグルやバイドゥがディープラーニング技術を使って、ユーザー投稿写真の画像を分類していると語っている。水面下で、かなり開発が進められているようだ。
ここで、最近公表されている画像認識のサンプル例を掲げておく。最初は、年初にピンタレストが買収したVisualGraphが示す画像認識例。VisualGraphは画像認識とビジュアル検索のスタートアップ。25人が描かれた画像から,20人の顔を自動認識した例である。人間なら25人の顔を簡単に認識できるが、まだ機械(コンピューター)だとそう簡単ではないということかも。

次はグーグルが、ディープラーニング技術を使って、ストリートビュー写真から家の番地を認識する例である。番地の数字は、縦書きや横書き、さらには斜め書きもあるし、サイズやフォントもまちまちであるだけに、かなり学習させる必要がある。テストでは、20万点の番地が含まれたストリートビュー写真を学習させた。機械学習のための写真のタグ付け(人手で番地付け)は、以前、reCAPUTUREを利用してユーザーに手伝ってもらっていたが、今回もそうかもしれない。
画像認識の壁は高そうだが、機械学習による画像認識の挑戦は真っ盛りである。

(2014年02月24日)
参考
・グーグルが推進する「人工知能のマンハッタン計画」(メディア・パブ)
・Social Media’s Big Data Future — From Deep Learning To Predictive Marketing(BusinessInsider)
・Pinterest, Yahoo, Dropbox and the (kind of) quiet content-as-data revolution(GIGAOM)
・How Facebook’s New Machine Brain Will Learn All About You From Your Photos(Popular Science)
・Google team’s neural network approach works on street numbers(Phys.org)
![]()